NES Emulation journal: I Can display something!
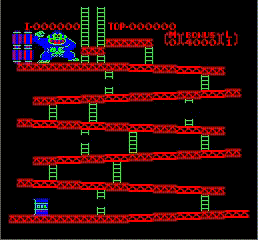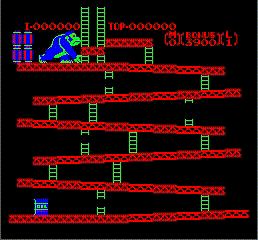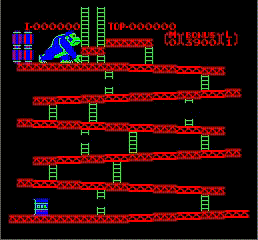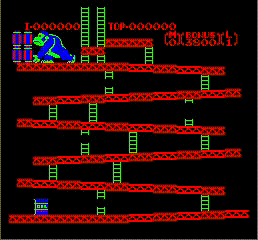
16 Dec 2018Got my first screen working! The colors are super wrong because I am not using the correct palette, and there is not sprite yet but this greatly encouraging.
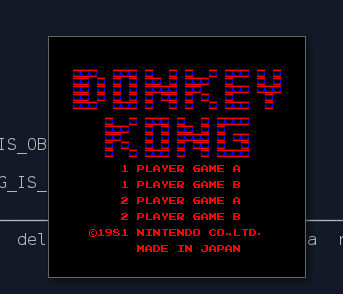
I spent a few hours debugging a black screen before getting to that result. The problem was that my interrupt handler was setting the program counter to the address located in 0xFFFC/0xFFFD, which is the reset vector, instead of 0xFFFA/0xFFFB.
Effectively, I was resetting the program every time NMI was triggered (at Vblank most of the time). I wonder what could I have done to avoid this situation. More unit testing? More ROM testing? Yea… I’ll take some time implementing tests with various test ROM.
Oh, and as a bonus, this is Donkey Kong trying to throw something…that cannot be displayed yet. Interesting, DK Kong is actually part of the background.